
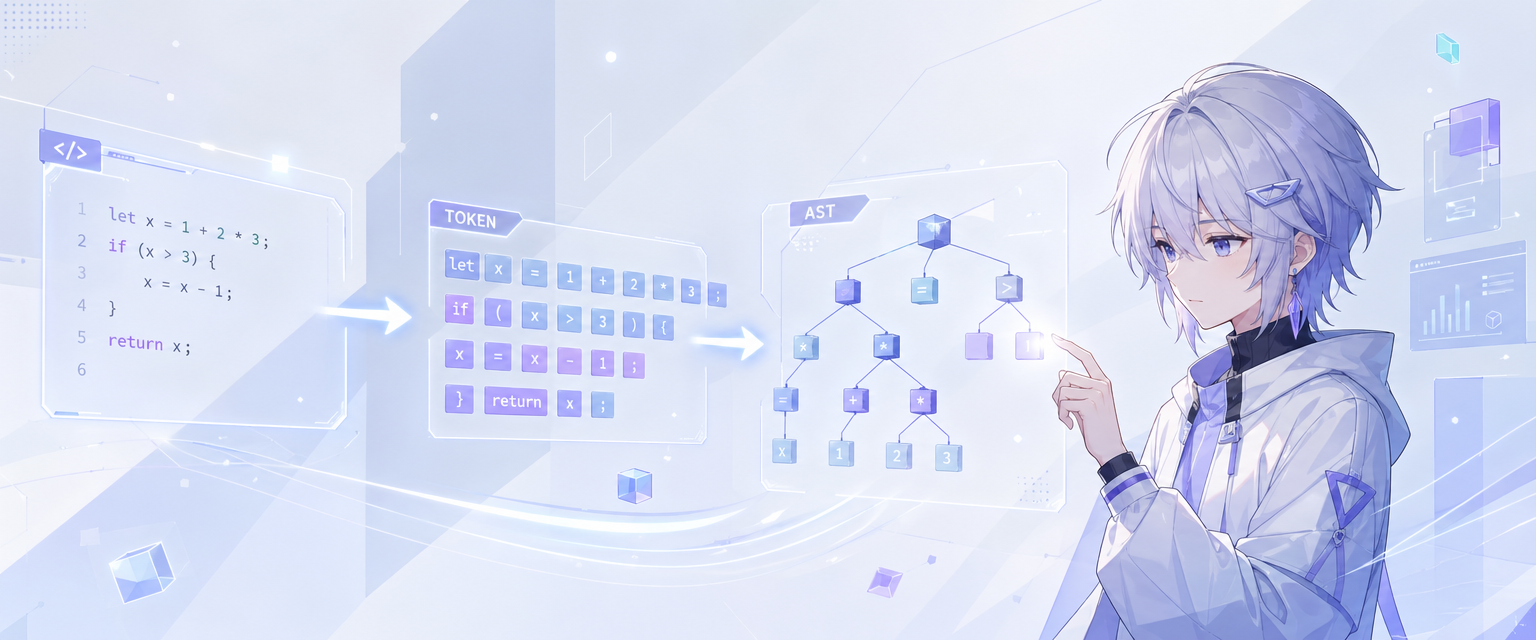
这是"哆来咪の编译器"系列的第一篇。这一篇要解决的问题是:把一段 C 语言风格的源代码,变成一棵结构化的抽象语法树(AST)。
做完这一步,我们的编译器就能"读懂"源代码了。
编译器前端是干什么的
编译器前端的工作,一句话说就是:把文本变成树。
你写下的源代码,对计算机来说只是一串字符。编译器要先把它理解成结构化的东西,才能继续做后面的检查、优化、代码生成。这个"理解"过程分两步:
- 词法分析:把字符流切成一个个 token(词法单元)
- 语法分析:把 token 流组织成一棵树(AST)
完成这两步再加上语义分析,就是完整的编译器前端。这一篇我们先讲词法分析和语法分析,AST 的结构也会一起介绍。
词法分析:把字符变成 token
token 是什么
token 是源码的最小有意义的单元。比如你写 int a = 1;,这句话会被切成这些 token:
| 源码 | token 类型 | 值 |
|---|---|---|
int |
INT(关键字) | - |
a |
IDENTIFIER(标识符) | "a" |
= |
ASSIGN(赋值) | - |
1 |
NUMBER(整数) | 1 |
; |
SEMICOLON(分号) | - |
空白字符和注释在词法分析阶段就被丢掉了,后面的阶段完全感知不到它们。
用 flex 实现词法分析器
我们用的是 flex,一个经典的词法分析器生成工具。你写的不是 C++ 代码,而是正则规则配动作,flex 会帮你生成完整的 C 代码。
举个例子,识别关键字的规则是这样的:
"int" { return INT; }
"void" { return VOID; }
"if" { return IF; }
"else" { return ELSE; }
"while" { return WHILE; }
"return" { return RETURN; }每匹配到一个关键字,就返回对应的 token 编号。解析器(bison)拿到这个编号就知道"编译器遇到了一个 int 关键字"。
数字的规则稍微复杂一点,因为我们要支持三种格式:
{HEXNUMBER} { yylval.num = strtol(yytext, nullptr, 0); return NUMBER; }
{OCTNUMBER} { yylval.num = strtol(yytext, nullptr, 0); return NUMBER; }
{DECNUMBER} { yylval.num = strtol(yytext, nullptr, 10); return NUMBER; }三种规则都返回 NUMBER token,但会把解析出来的整数值存到 yylval.num 里,这样后续的语法分析阶段就能拿到这个数字的具体值了。
标识符也是类似思路,匹配到 [a-zA-Z_][a-zA-Z_0-9]* 模式的字符串后,把它存成 std::string*,返回 IDENTIFIER token。
词法分析器内部:状态机是怎么跑的
flex 生成的词法分析器,本质是一个 DFA(确定性有限自动机)。它一次读一个字符,根据当前状态和读到的字符决定跳到哪个下一状态。
光说概念不直观,我们直接看一个具体例子。假设我们要识别关键字 int、标识符、数字和空白,flex 内部会编译出一张状态转移表,简化后长这样:
空白 字母 数字 其他
───── ───── ───── ─────
状态 0: 0 2 3 输出token ← 初始状态
状态 2: 输出 2 2 输出token ← 标识符/关键字状态
状态 3: 输出 输出 3 输出token ← 数字状态其中状态 0 是起始状态,状态 2 和状态 3 在遇到不匹配的字符时会输出 token 并回到状态 0。
现在拿输入 int a = 1; 逐字符走一遍:
读 i:状态 0 → 2。当前"可能"在匹配 int 关键字,也可能是一个叫 intSomething 的标识符,flex 还不敢确定。
读 n:状态 2 → 2。还是在候选里。
读 t:状态 2 → 2。依旧没排除标识符的可能。
读到空格:状态 2 上空格没有转移,说明这条路走不下去了。但这不代表匹配失败——状态 2 是一个接受状态,当前已读入的 int 可以作为一个完整的 token 输出。接下来 flex 要做三件事:
- 在所有能匹配
int的规则里,选最长的那条 - 把多余的字符(这里就是空格)退回输入流
- 回到状态 0,准备匹配下一个 token
这里有个关键规则:最长匹配。int 这个字符串,它既匹配关键字 "int",也匹配标识符规则 [a-zA-Z_][a-zA-Z_0-9]*。两条都能匹配 3 个字符,长度一样,这时候 flex 选在 .l 文件里写在前面的那条——所以我们必须把关键字规则写在标识符规则前面,保证 int 被识别为关键字而不是标识符。但如果输入是 intVar,标识符规则能匹配 6 个字符,关键字只能匹配 3 个,最长匹配胜出,输出标识符。
继续走后面的输入:
读到空格:状态 0 → 0。空白在初始状态就被吞掉了。
读 a:状态 0 → 2。新的标识符开始。
再次读到空格:状态 2 没有空格的转移,输出 IDENTIFIER("a"),回到状态 0。
读 =:状态 0 没有 = 的转移(在简化表里归到"其他"),直接输出 ASSIGN token。
再读到空格:吞掉。
读 1:状态 0 → 3。数字状态开始。
读 ;:状态 3 没有 ; 的转移,输出 NUMBER(1),回到状态 0。
读 ;:状态 0 没有对应转移,输出 SEMICOLON。
整个过程就是:逐字符查表跳状态 → 撞墙时截取最长匹配 → 执行规则动作 → 回退 → 从头再来。
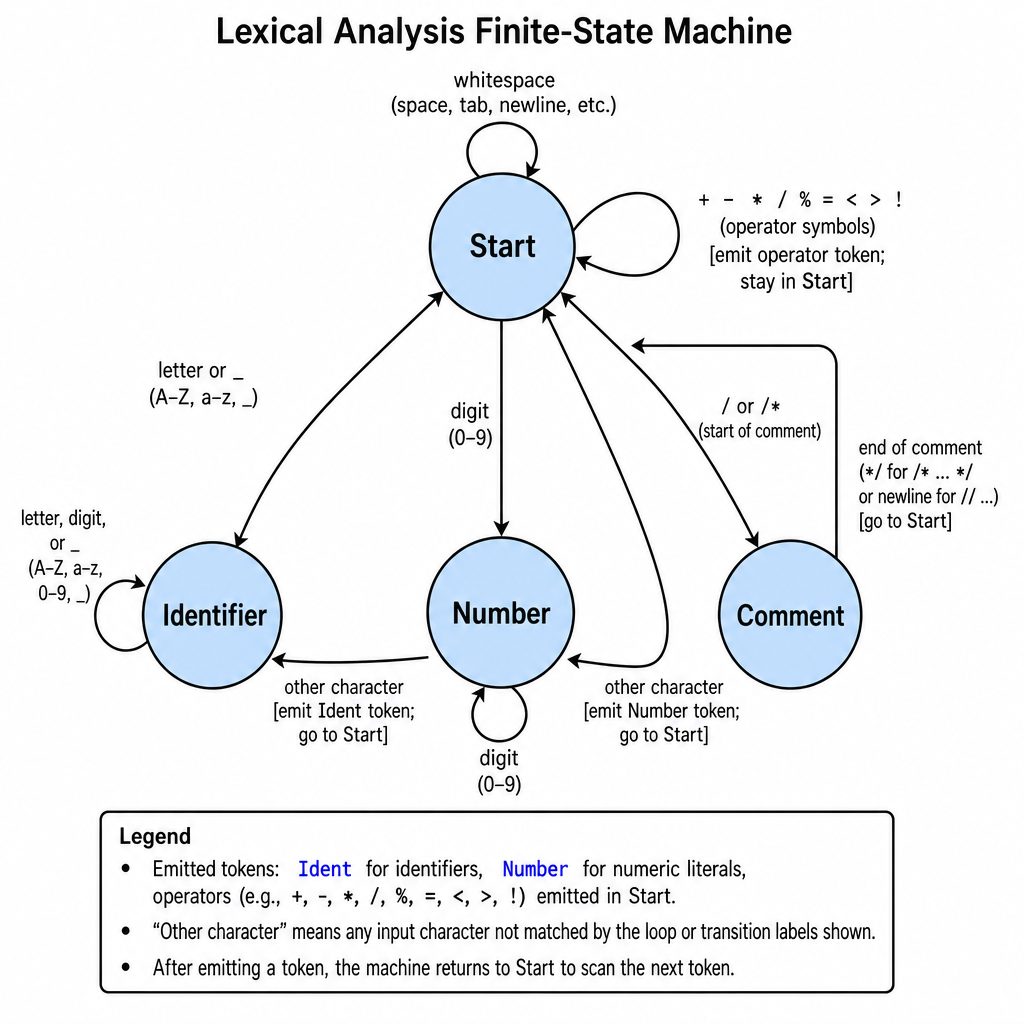
flex 在生成 C 代码时,把这几步编译成一个紧凑的循环,核心逻辑大概是:
while (1) {
int next = transition_table[state][input_char];
if (next == NO_TRANSITION) {
execute_action(last_accepting_state);
yyunput(chars_since_last_accept); // 退回多读的字符
state = 0;
} else {
state = next;
input_char = next_input_char();
}
}显式状态:多行注释
除了 DFA 内部这张隐式的状态转移表,flex 还支持我们手动声明状态——在 flex 里叫 start condition。我们的词法分析器里就用了一个来处理多行注释。
注释和空白
注释不是 token,它们在词法分析阶段就被干掉了。对于单行注释 //...,直接整行忽略。多行注释 /* ... */ 麻烦一点,需要用一个 flex 状态(start condition)来处理:
"//".* { /* ignore */ }
"/*" { BEGIN(COMMENT); }
<COMMENT>"*/" { BEGIN(INITIAL); }
<COMMENT>. { /* ignore */ }
<COMMENT>\n { /* ignore */ }进入 /* 后切到 COMMENT 状态,遇到 */ 切回来,中间所有字符包括换行都直接忽略。
遇到非法字符怎么办
简单粗暴:报错并退出。在 flex 规则最下面放一条 . 匹配所有未识别的字符:
. { fprintf(stderr, "Lexical error: unexpected character '%s' at line %d\n",
yytext, yylineno);
exit(1); }第一次写编译器不用太纠结错误恢复,先把正确路径跑通最重要。
语法分析:把 token 变成 AST
语法规则和上下文无关文法
词法分析把字符变成了 token 序列,但 token 序列还是扁平的。int a = 1 + 2; 这句话,语法分析器需要识别出:"这是一个变量声明语句,变量名是 a,初始化表达式是一个加法操作,左操作数是 1,右操作数是 2"。
我们怎么告诉分析器这些结构?用语法规则。
比如一个 return 语句,规则可以这样写:
Stmt : RETURN Expr ';'读作:一个语句(Stmt)可以由 return 关键字、一个表达式(Expr)和一个分号组成。
表达式又递归地定义:
Expr : Expr '+' Expr
| Expr '-' Expr
| Expr '*' Expr
| ...
| NUMBER
| IDENTIFIER这就是上下文无关文法(CFG)。它用产生式(production)递归地描述语言的语法结构。
用 bison 实现语法分析器
我们用 bison,它和 flex 是同一生态的。你写 .y 文件定义语法规则,每条规则后面跟一段 C++ 代码——这条规则匹配成功时要干什么。
来看一个实际规则,解析变量声明:
VarDecl
: INT IDENTIFIER OptInitExpr OptMoreVarDefs SEMICOLON {
VarDeclStmt* decl = new VarDeclStmt(Type::Int());
VarDef* first = $3 ? new VarDef(*$2, $3) : new VarDef(*$2);
decl->defs.emplace_back(first);
if ($4) {
for (auto* def : *$4) {
decl->defs.emplace_back(def);
}
delete $4;
}
delete $2;
$$ = static_cast<ASTNode*>($1); // 这个 $1 需要修正,返回 decl
}看不懂 $$、$2、$3 没关系,这是 bison 的约定:$$ 是这条规则的结果值,$1 到 $N 是规则右边第 1 到第 N 部分的返回值。本质上就是在匹配成功时,新建对应的 AST 节点,然后把子节点挂上去。
运算符优先级怎么办
1 + 2 * 3 应该解析成 1 + (2 * 3) 而不是 (1 + 2) * 3。在 bison 里,不需要写复杂的规则来处理这个,直接用 %left 和 %right 声明优先级就行:
%left PLUS MINUS
%left STAR SLASH PERCENT写在越下面的优先级越高。所以这里的乘法(STAR SLASH PERCENT)优先级高于加法(PLUS MINUS)。bison 会自动处理移进-归约冲突,按优先级选择正确的解析方式。
AST:编译器理解的"程序面貌"
AST 长什么样
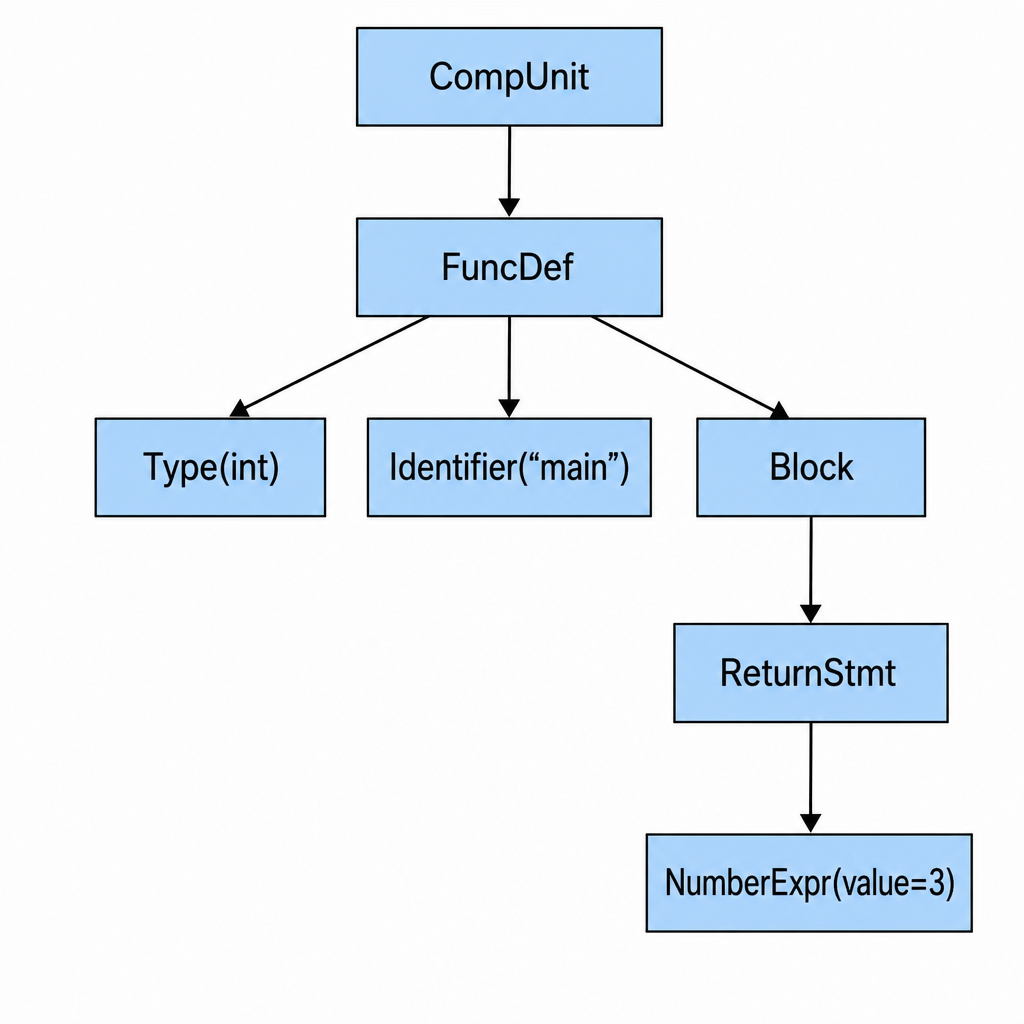
经过词法分析和语法分析,我们得到了抽象语法树(Abstract Syntax Tree)。
以最简单的一个程序为例:
int main() {
return 3;
}它的 AST 是:
CompUnit
└── FuncDef (name: "main", returnType: int)
└── Block
└── ReturnStmt
└── NumberExpr (value: 3)CompUnit(编译单元)是整棵树的根节点,它包含若干个顶层项(函数定义或全局变量声明)。每个函数定义(FuncDef)包含一个名字、一个返回类型、一组参数、和一个函数体(Block)。函数体是一组语句的列表,这里只有一条 ReturnStmt,它又包含一个表达式 NumberExpr。
关键的地方在于:源代码的嵌套结构直接映射为树的嵌套结构。这就是"结构化"的含义。
我们的 AST 节点类型
我们的编译器目前支持 12 种 AST 节点,分三大类:
表达式(Expr):
• NumberExpr:整数字面量,比如 3、0xFF
• IdentifierExpr:变量引用,比如 a、sum
• ParenExpr:括号表达式 (expr)
• FunctionCallExpr:函数调用,比如 foo(a, b)
• UnaryExpr:一元操作,-, +, !
• BinaryExpr:二元操作,+, -, *, /, %, <, >, <=, >=, ==, !=, &&, ||
语句(Stmt):
• Block:用花括号包裹的语句序列
• EmptyStmt:空语句(单个分号)
• ExprStmt:表达式语句(表达式加分号)
• AssignStmt:赋值语句 a = expr
• VarDeclStmt:变量声明语句 int a = 1, b = 2;
• IfStmt:if (cond) then [else else_branch]
• WhileStmt:while (cond) body
• BreakStmt / ContinueStmt:循环控制
• ReturnStmt:return [value]
顶层结构:
• FuncDef:函数定义,包含返回类型、名字、参数列表、函数体
• CompUnit:编译单元(整棵树的根节点)
所有权和内存管理
我们用了 std::unique_ptr 来管理 AST 节点的所有权。语法分析器用 new 分配节点,然后立即交给 unique_ptr 管理。这样不需要手动 delete,树销毁时所有子节点自动回收。
Visitor 模式遍历 AST
有了 AST 之后,怎么做各种分析和变换呢?我们用了访问者模式(Visitor pattern)。
核心思想很简单:定义一个 ASTVisitor 接口,里面对每种 AST 节点都有一个 visit() 方法。每个 AST 节点的 accept() 方法只干一件事——调用 visitor->visit(this)。
// 比如在 NumberExpr 里:
void NumberExpr::accept(ASTVisitor* visitor) {
visitor->visit(this);
}这看起来像是一个多余的跳转(我调用你,你又调用回我),但它的好处是:C++ 的虚函数分发会自动选择正确的 visit() 重载版本。你写一个新的分析 pass,比如"常量折叠"、"类型检查"、"代码生成",只需要实现一个新的 Visitor 子类即可,不需要改 AST 节点本身。
这是"对扩展开放、对修改关闭"(开放-封闭原则)的一个经典实现。
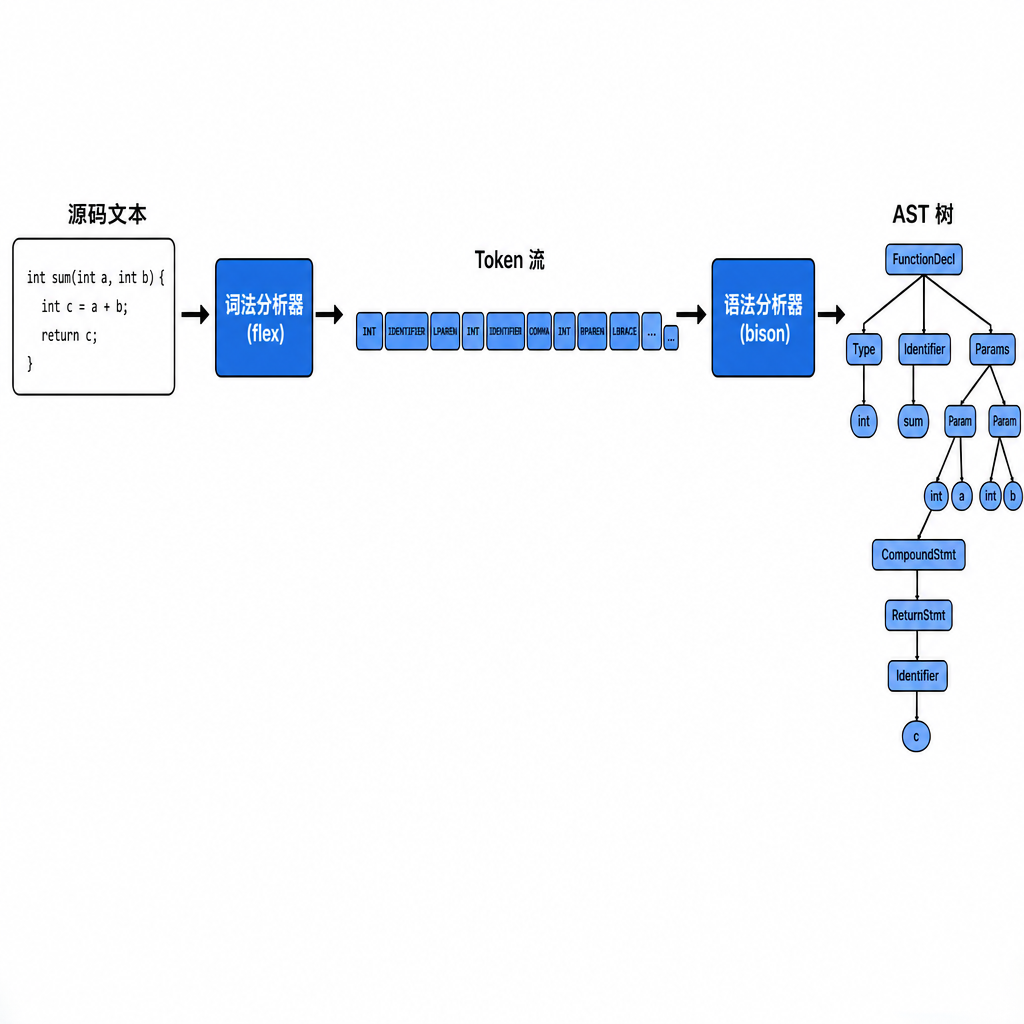
整个流程串联
从源代码到 AST,完整的调用链路是这样:
stdin (源码文本)
│
▼
yyparse() ← bison 生成的解析器入口
│
├── yylex() (flex 生成) ← 每次调用返回一个 token
│ ├── 跳过空白和注释
│ ├── 匹配关键字 → 返回 token 编号
│ ├── 匹配标识符 → 存字符串 → 返回 IDENTIFIER
│ └── 匹配数字 → 存整数值 → 返回 NUMBER
│
└── 语法规则语义动作 ← 匹配时新建 AST 节点
new CompUnit()
new FuncDef(...)
new IfStmt(...)
...
│
▼
root (CompUnit*) ← 全局指针,指向整棵 ASTmain.cpp 里我们只做了一行调用:
if (yyparse() != 0) return 1;解析成功,全局变量 root 就指向了完整的 AST。之后的所有工作——语义分析、IR 生成、优化、代码生成——都在这棵树上进行。
总结
这一篇我们完成了编译器的前端基础:词法分析器(flex)把源码切成 token 流,语法分析器(bison)把 token 流组织成 AST。
现在我们的编译器可以把一篇 .sy 文件读进来、理解它的结构、在内存里建立起一棵完整的抽象语法树。虽然它还不能做任何检查和翻译,但它是后续所有步骤的基础。
下一篇我们会做语义分析:变量是否先声明再用、类型是否匹配、函数调用参数是否对得上——这些问题的检查都在 AST 上进行。
Comments NOTHING